Fault tolerance for live HLS converted just in time (JIT)
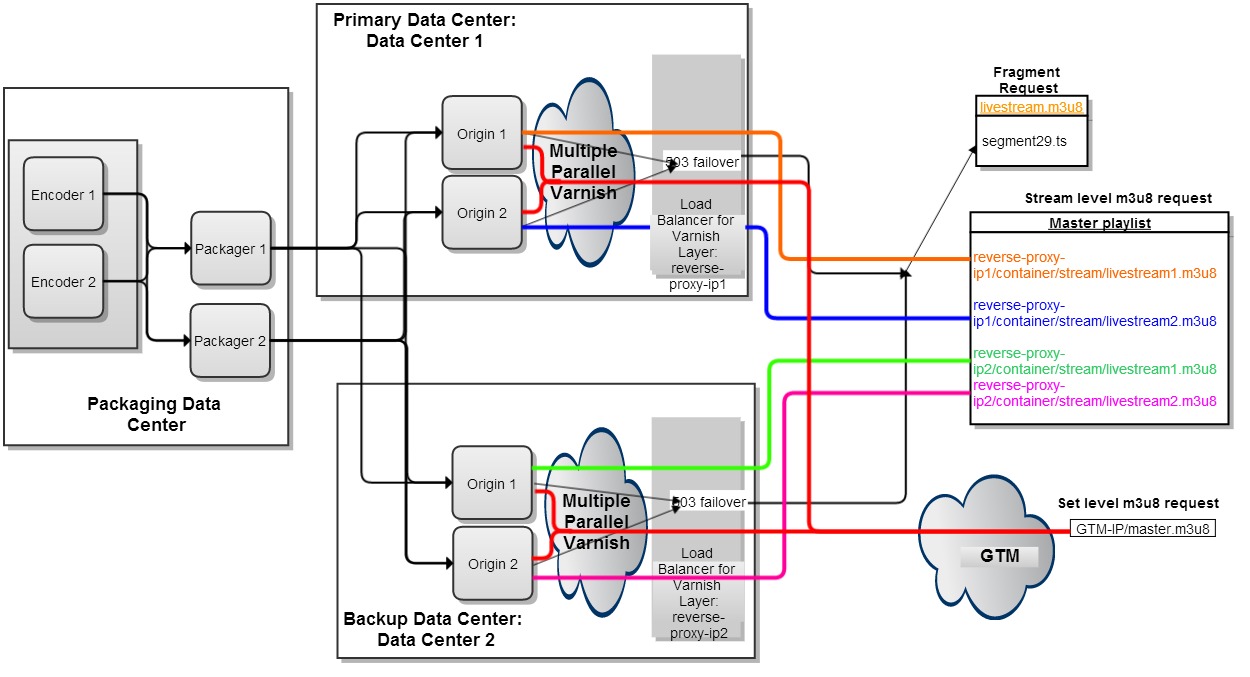
Unlike HDS, the segment URLs are listed in the HLS manifest and cannot be predicted using a pre-defined template. Therefore, it is difficult to support BEF at client side where the URL of a missing fragment must be constructed at the player. Another HLS requirement that makes client-side BEF support impossible is that a gap or a fragment, once advertised in the HLS manifest, cannot be removed in a later refresh operation. Primetime Origin provides fault tolerance for HLS created just-in-time from HDS content pushed from Packagers/Encoders. It utilizes server side redundancy to implement healing from transient failures. Consider a scenario where the advertised manifest reflects the global state of the system by including fragments that may be present on another origin server. In this case, the client can obtain the advertised fragments from any origin server through the reverse proxy using the 503 failover technique.
Each origin server maintains a copy of the M3U8 (HLS manifest). It is updated not on the basis of fragments received. Instead, it is updated by extending it with any subsequent fragment entries in the F4M (HDS manifest), generated at and pushed from the packager. You perform this operation consistently so that only the subsequent fragment-URLs are added. Updating this way makes the manifest consistent across client-requests and the origin server need not guess the URLs of missing fragments. If an origin server is unavailable for some time, it is able to recover the missing fragment entries from the packager's manifest. The system also handles a transient fault at packager seamlessly because each origin receives manifests and fragments from multiple packagers.
If the source F4M, which is pushed by a packager, contains a gap (missing fragments) near the live edge, the origin will not update its manifest immediately to include the gap. Instead, it will wait for the next manifest push from a packager. This helps when the origin receives a manifest from another packager that has fragment entries instead of the gap. Even if the packagers are out-of-sync by a few fragments, the fragments dropped by the leading packager do not result in gap entries in the M3U8 (created just-in-time at origin) if another packager creates the fragments. Figure 3 illustrates how adaptive wait, while updating M3U8 just-in-time, mitigates occasional fragment drops at packagers.

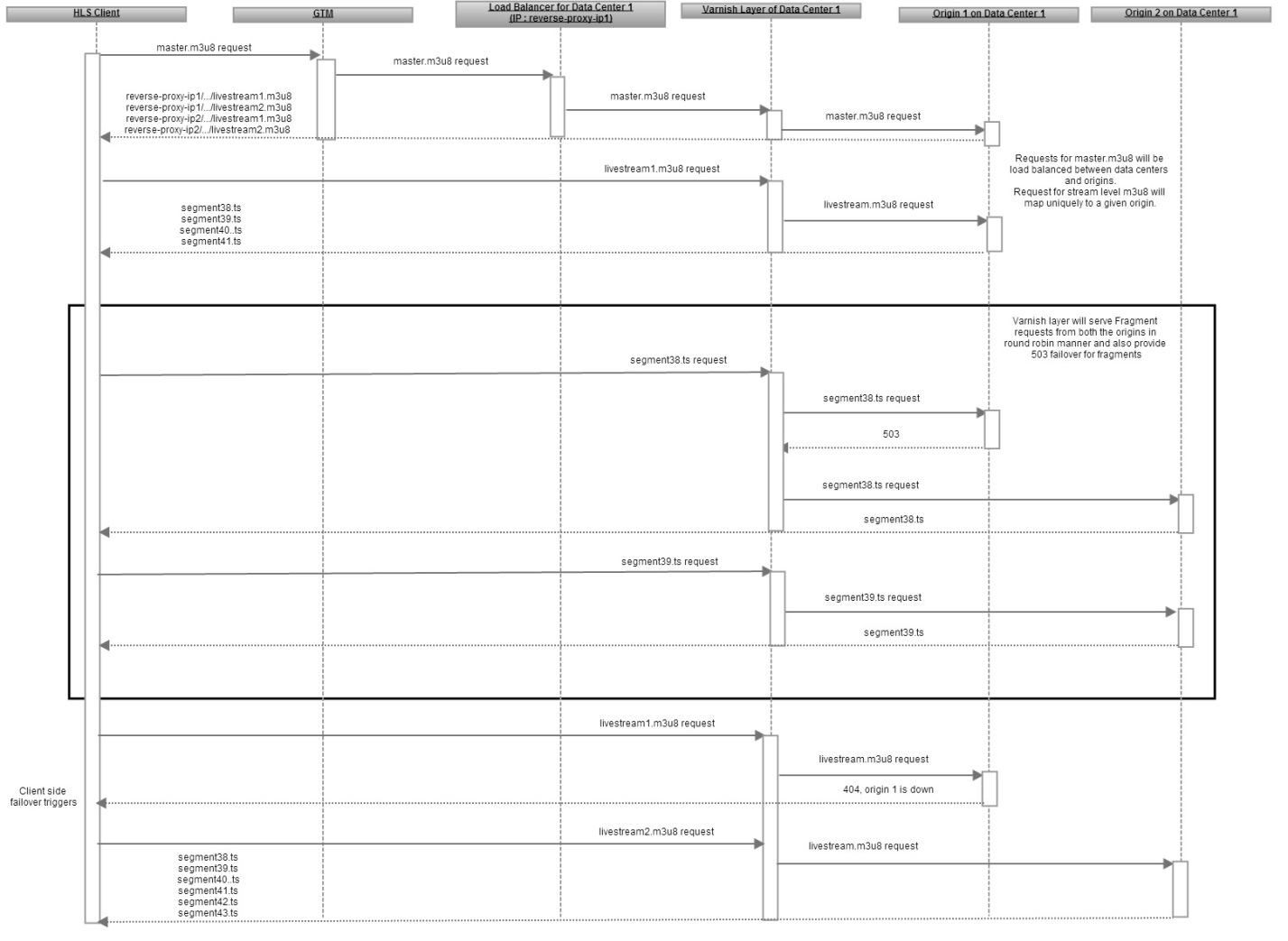
To ensure the consistency of HLS manifest, 503 failover is enabled for HLS fragments only and not for stream level M3U8. For the sample setup (Figure 4), the top-level manifest or master m3u8 contains a URL corresponding to each origin server. To avoid client driven failover, you configure the reverse proxy (varnish cache) with a grace period to allow for the serving of stale m3u8 for a few seconds when the serving origin server goes down or is out-of-network.
This scheme doesn't handle all scenarios where multiple transient faults occur simultaneously. For example, the system may reject a request for Fragment3 with a 404 error when Origin1 is down when a fragment request is served and Origin2 is down when the packagers are pushing Fragment3.
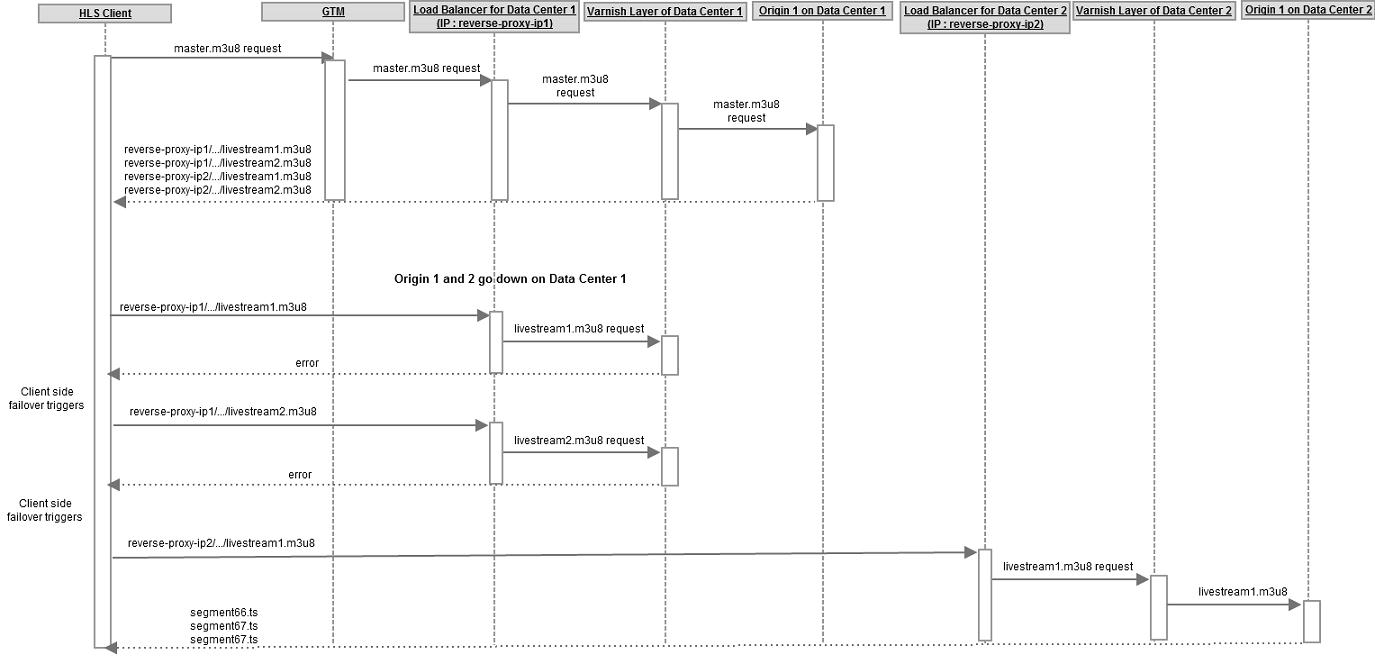
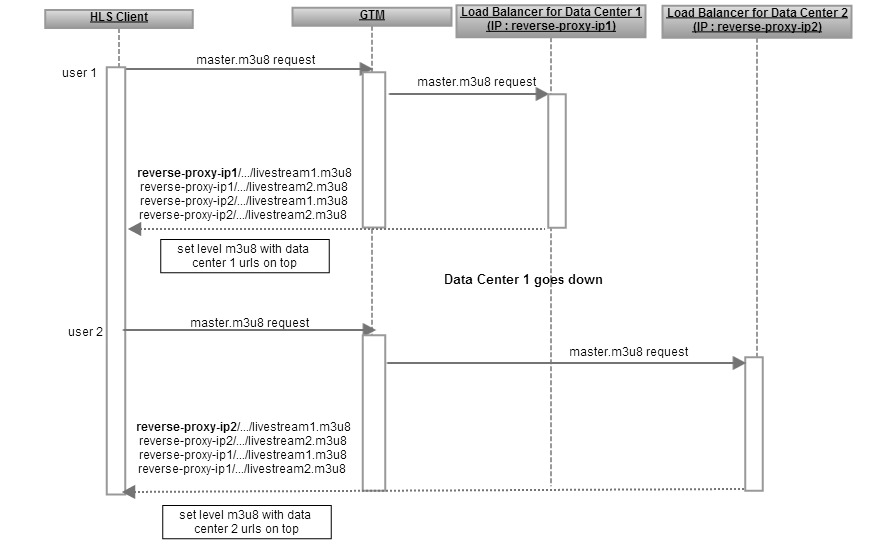
Because the probability of the occurrence of a fault is low, we assume that the probability of two or more faults occurring simultaneously will be negligible. Client-side-failover is employed to handle faults that are not recovered at the origin layer.
Figures 5, 6 and 7 describe the sequence flow for various failure scenarios and how 503 failover, data-center failover via GTM, and client-driven failover work together to achieve uninterrupted and seamless HLS playback despite faults.